はじめに
Goで自作RDBMSに挑戦してみたログです。自作、といっても大部分は参考にした書籍の移植です。
ここ1年くらいRDBに向き合う機会が多く、その内部実装を手を動かしながら身を持って理解してみたいというモチベーションから始めてみました。ちょうど会社の『内部構造から学ぶPostgreSQL』読書会に参加したこともモチベーション上げるきっかけとなりました。
(他の方の記事ですが、読書会の記録はこちら↓)
- 『内部構造から学ぶPostgreSQL』読書会を完走した感想
- [改訂3版]内部構造から学ぶPostgreSQLの社内読書会振り返り
- データベースをデータの箱としか思っていなかった私の『内部構造から学ぶPostgreSQL』を読んだ感想
普段何気なく使ってるRDBMSですが、ACID特性を守るため・大量の読み書きを捌くため、非常に緻密に設計されております。 これを完全再現といかなくとも自分の手で実装できると、より解像度高く業務でも利用、はたまた複雑な実装に対する手立てが増やせると思い自作に取り組みはじめました。
本記事では成果物について紹介し、その実装の進め方やTips・所感についてまとめてみます。
成果物
リポジトリはこちら。バグも多く残ってて実用用途からは遠いですがとりあえず動きます。
abekoh/simple-db: Implementation of the SimpleDB database system in Go.
機能一覧
基本は”Database Design and Implementation”の実装を移植、一部機能(*がついたもの)を自力で追加しました。
- SELECT
- WHERE 演算子は
=のみ - JOIN (INNER JOINのみ)
- ORDER BY
- *プランナに使われてなかったので、使えるようにした
- GROUP BY
- 集計関数はCOUNT, MAX, MIN, SUM
- *プランナに使われてなかったので、使えるようにした
- WHERE 演算子は
- INSERT
- UPDATE
- 更新対象フィールドは1つのみ
- WHERE 演算子は
=のみ
- DELETE
- WHERE 演算子は
=のみ
- WHERE 演算子は
- CREATE TABLE
- CREATE VIEW
- CREATE INDEX
- B-Treeインデックス
- データ型
- INT(32bit)、VARCHARのみ
- メタデータテーブル
table_catalog,field_catalog,view_catalog,index_catalog
- トランザクション
- COMMIT, ROLLBACK
- 分離レベルはREAD UNCOMMITTED、Dirty Readあり
- *Prepared Statement
- *PostgreSQL プロトコル
- 各種PostgreSQLドライバ、
psqlコマンドでも使えるようにした
- 各種PostgreSQLドライバ、
- *EXPLAIN
デモ
CREATE TABLE、INSERT、SELECT、UPDATE、DELETEが一通り動きます。 明示的なトランザクション発行・ROLLBACKも可能です。
❯ psql -h localhost -p 45432
psql (14.11 (Homebrew), server 0.0.0)
Type "help" for help.
abekoh=> CREATE TABLE departments (department_id INT, department_name VARCHAR(20));
CREATE TABLE
abekoh=> CREATE TABLE students (student_id INT, name VARCHAR(10), major_id INT, grad_year INT);
CREATE TABLE
abekoh=> INSERT INTO students (student_id, name, major_id, grad_year) VALUES (1, 'Alice', 1, 2018);
INSERT 0 1
abekoh=> INSERT INTO students (student_id, name, major_id, grad_year) VALUES (2, 'Bob', 1, 2020);
INSERT 0 1
abekoh=> SELECT student_id, name FROM students;
student_id | name
------------+-------
1 | Alice
2 | Bob
(2 rows)
abekoh=> SELECT student_id, name FROM students WHERE student_id = 1;
student_id | name
------------+-------
1 | Alice
(1 row)
abekoh=> UPDATE students SET name = 'Adam' WHERE student_id = 1;
UPDATE 1
abekoh=> SELECT student_id, name FROM students;
student_id | name
------------+------
1 | Adam
2 | Bob
(2 rows)
abekoh=> DELETE FROM students WHERE student_id = 1;
DELETE 1
abekoh=> SELECT student_id, name FROM students;
student_id | name
------------+------
2 | Bob
(1 row)
abekoh=> BEGIN;
BEGIN
abekoh=> UPDATE students SET name = 'BOB' WHERE student_id = 2;
UPDATE 1
abekoh=> SELECT student_id, name FROM students;
student_id | name
------------+------
2 | BOB
(1 row)
abekoh=> ROLLBACK;
ROLLBACK
abekoh=> SELECT student_id, name FROM students;
student_id | name
------------+------
2 | Bob
(1 row)JOIN, GROUP BY, ORDER BYも実装。
abekoh=> SELECT name, department_name FROM students JOIN departments ON major_id = department_id;
name | department_name
---------+------------------
Alice | Computer Science
Bob | Computer Science
Charlie | Computer Science
David | Mathematics
Eve | Mathematics
(5 rows)
abekoh=> SELECT department_name, MIN(grad_year) AS min_grad_year FROM students JOIN departments ON major_id = department_id GROUP BY department_name ORDER BYdepartment_name;
department_name | min_grad_year
------------------+---------------
Computer Science | 2007
Mathematics | 1999
(2 rows)実行計画も確認可能。INDEXありなしで変化します。複雑なクエリの実行計画は壮観です。
abekoh=> EXPLAIN SELECT student_name FROM students WHERE student_id = 3901;
QUERY PLAN
--------------------------------------------------
Project fields=student_name (ba=770,ro=2) +
Select predicate=student_id=3901 (ba=770,ro=2)+
Table table=students (ba=770,ro=10000)
(1 row)
abekoh=> CREATE INDEX students_pkey ON students (student_id);
SELECT 0
abekoh=> EXPLAIN SELECT student_name FROM students WHERE student_id = 3901;
QUERY PLAN
------------------------------------------------------------
Project fields=student_name (ba=2,ro=2) +
Select predicate=student_id=3901 (ba=2,ro=2) +
IndexSelect index=students_pkey,value=3901 (ba=2,ro=2)+
Table table=students (ba=770,ro=10000)
(1 row)
abekoh=> EXPLAIN SELECT department_name, MIN(grad_year) AS min_grad_year FROM students JOIN departments ON major_id = department_id GROUP BY department_name ORDER BY department_name;
QUERY PLAN
--------------------------------------------------------------------------------------------------------
Project fields=department_name,min_grad_year (ba=2,ro=34) +
Sort sortFields=department_name (ba=2,ro=34) +
GroupBy groupFields=department_name,aggregationFuncs=MIN(grad_year) AS min_grad_year (ba=36,ro=34)+
Sort sortFields=department_name (ba=36,ro=299) +
Select predicate=major_id=department_id (ba=776,ro=299) +
MultiBufferProduct (ba=776,ro=1000000) +
Table table=students (ba=770,ro=10000) +
Table table=departments (ba=6,ro=100)
(1 row)また、Prepared Statement・PostgreSQL拡張プロトコルにも対応させたので、こちらのテストコードのようにデフォルト設定・自然なコードで接続・クエリ発行ができるようなってます。
simple-db/internal/postgres/server_test.go at main · abekoh/simple-db
アーキテクチャ
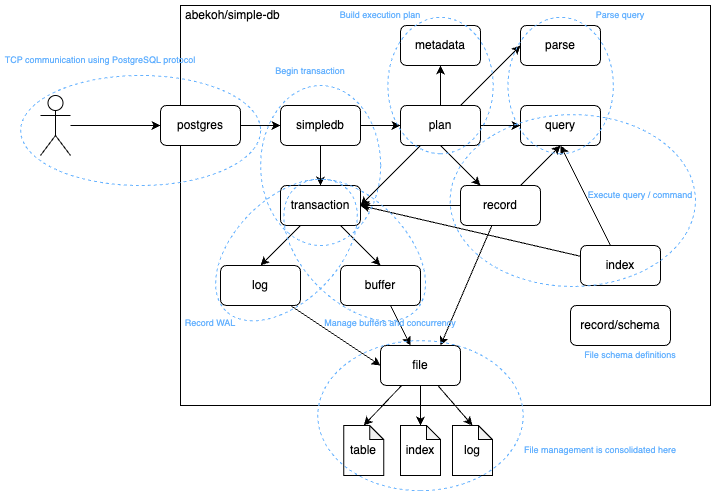
パッケージ単位のざっくりの依存・役割を図示してみたものです。正確にはもっと矢印が増える・関係する箇所は多くなりますが、あくまでイメージで。
実用されているRDBMSみたく、フロントエンド・パーサ・プランナ・エグゼキュータと一通り揃ってます。パッケージ構成は元のコードからはもろもろ変更し、よりシンプルにしております。(循環参照排除などの兼ね合いもあってなくなく対応した箇所も多いです。)
参考文献: “Database Design and Implementation”
自作RDBMSをやっていくにあたって、こちらの書籍を主に参考にしてきました。 昨年末にセールで1000円程度で買えてラッキーでした。
Database Design and Implementation: Second Edition | SpringerLink
「自作RDBMS」と検索して出てくる『自作RDBMSやろうぜ!』でも紹介されていたもので、この1冊沿っていけばそれっぽいのができそうとのことで採用。Javaによるサンプルコードがあるのも嬉しいポイントです。
目次は以下の通り。概要の後にディスク・ファイル管理の話から始まり、上のレイヤーに進んでいく感じ。一通りクエリが動くようになったところで、インデックスやソート、その他最適化の話に繋がります。
- Chapter 1: Database Systems
- Chapter 2: JDBC
- Chapter 3: Disk and File Management
- Chapter 4: Memory Management
- Chapter 5: Transaction Management
- Chapter 6: Record Management
- Chapter 7: Metadata Management
- Chapter 8: Query Processing
- Chapter 9: Parsing
- Chapter 10: Planning
- Chapter 11: JDBC Interfaces
- Chapter 12: Indexing
- Chapter 13: Materialization and Sorting
- Chapter 14: Effective Buffer Utilization
- Chapter 15: Query Optimization
Table of contents of “Database Design and Implementation”
進め方
基本は書籍の順番どおり、ざっくり読む→Javaのサンプルコードを参考にしつつGoで実装→理解できていないところをもう一度読んで理解深める、という流れで進めました。 とにかく動かしたい!という思いでひたすらコード書いてくことでモチベーション維持できた気がします。難しい箇所はほぼそのまま移植になってしまってますが…
Goで書いていくにあたって、気をつけた点は以下の通り。
- 並行処理はGoらしく、Channelをできるだけ活用
- err, okなど戻り値で異常系を判別できるように
- 無理に関数・structを分離しない
- サンプルコードはかなりオブジェクト指向に前のめり?で、クラス化するほどでないな〜というところも多くあった。不要と判断したところはフラットになるよう書き換えた
- テストコードしっかり書く
- サンプルコードでもテストは多め。ただ期待値検証ができていないことが多いので追加
- 循環参照解消させるようにパッケージを変更
Tips
後学のためになりそうなところをいくつか取り上げます。
PostgreSQL プロトコル
書籍だと接続に関連するところ、いわゆるフロントエンドはJDBCドライバの実装になってます。 今回はユーザ側もGoで接続できることを目標にしたのでJDBCは扱わず、代わりにPostgreSQL プロトコルを採用することにしました。
PostgreSQL プロトコルに対応させることで、PostgreSQLのドライバをそのまま使えることはもちろん、psqlでインタラクティブにクエリ実行もできるようになります。
PostgreSQL プロトコルの概要は公式ドキュメントや以下の記事でキャッチアップ。
サーバ・プロトコルを実装するために、jackc/pgxを利用しました。 jackc/pgxにはPostgreSQLサーバ実装ができる要素も含まれております。以下のコードがPostgreSQLのモックサーバ実装の例になります。
pgx/pgproto3/example/pgfortune at master · jackc/pgx
あと、PostgreSQL プロトコルにはSimple QueryとExtended Queryの2種類があり、psqlで実行するような単純なクエリだけでよければ前者のみ実装でよいが、Prepared Statementを利用したクエリの場合は後者にも対応させなければなりませんでした。
「Goで自然なクエリを実行できるようにしたい」「conn.Exec(ctx, "INSERT INTO mytable (id, name) VALUES ($1, $2)", 1, "foo")みたいなコードも動かしたい
」という目標なので、Extended Query経由のPrepared Statementにも対応させました。
関連するのは以下の箇所など。Simple Queryならpgproto3.Queryだけで処理できますが、Exntended Queryであればpgproto3.Parse,pgproto3.Bind,pgproto3.Executeなどが1度のリクエストで処理されます。
そもそも本家がどういう通信しているかについて。ドキュメントだけだと読み取りにくいため、PostgreSQLを実際に動かしてクエリを叩き、WireSharkで眺めてみるというやり方で理解を進めました。ProtocolカラムにPGSQLと出ているようにしっかり対応されてて捗りました。
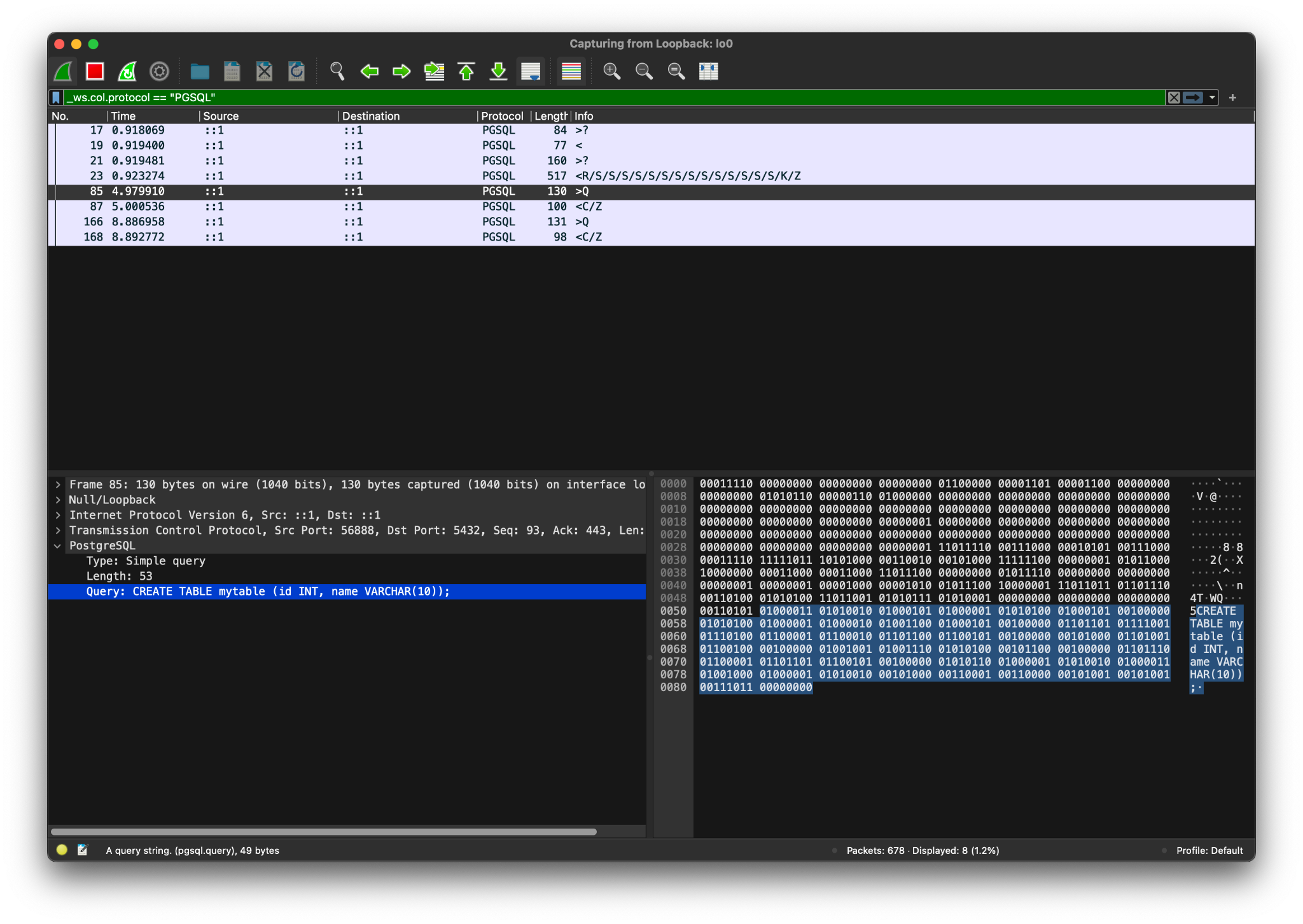
実行計画の出力
書籍のChapter 15では、クエリ最適化のためのプランナ構築について解説されています。そこで紹介されているヒューリスティックなアプローチ・DP使ったアプローチなど面白いんですが、実装してもそれが正しく動いているのかわかりません。
EXPLAINで実行計画が見れたほうがいいな〜と思い実装してみました。結果を眺めるのはもちろん、以下のテストコードようにプランナの結果検証にも役立ちます。
B-TreeのDump
実装が特に難しかったのがB-Treeインデックス。結局ほぼ写経になりました。 うまく動かない場合どこがミスっているのかチェックしにくく、デバッグ用に都度Dumpさせると検証しやすかったです。
simple-db/internal/index/btree.go at 74cb9358738f78194694c8b7aa8fe6f81b58e190 · abekoh/simple-db
↓みたいにキー、値などをテストで出力できるようにしてます。
Level: 1
Keys: [<empty> bbbbb53]
Children: [
Level: 0
Keys: [<empty> BBBBB27 DDDDD29 FFFFF187 HHHHH33 JJJJJ139 KKKKK36 MMMMM194 OOOOO40 QQQQQ198 SSSSS44 UUUUU150 VVVVV99 XXXXX49 aaaaa0]
Vals: [AAAAA130 AAAAA182 AAAAA234 AAAAA26 AAAAA78 BBBBB131 BBBBB183 BBBBB235 | BBBBB27 BBBBB79 CCCCC132 CCCCC184 CCCCC236 CCCCC28 CCCCC80 DDDDD133 DDDDD185 DDDDD237 | DDDDD29 DDDDD81 EEEEE134 EEEEE186 EEEEE238 EEEEE30 EEEEE82 FFFFF135 | FFFFF187 FFFFF239 FFFFF31 FFFFF83 GGGGG136 GGGGG188 GGGGG240 GGGGG32 GGGGG84 HHHHH137 HHHHH189 HHHHH241 | HHHHH33 HHHHH85 IIIII138 IIIII190 IIIII242 IIIII34 IIIII86 | JJJJJ139 JJJJJ191 JJJJJ243 JJJJJ35 JJJJJ87 KKKKK140 KKKKK192 KKKKK244 | KKKKK36 KKKKK88 LLLLL141 LLLLL193 LLLLL245 LLLLL37 LLLLL89 MMMMM142 | MMMMM194 MMMMM246 MMMMM38 MMMMM90 NNNNN143 NNNNN195 NNNNN247 NNNNN39 NNNNN91 OOOOO144 OOOOO196 OOOOO248 | OOOOO40 OOOOO92 PPPPP145 PPPPP197 PPPPP249 PPPPP41 PPPPP93 QQQQQ146 | QQQQQ198 QQQQQ250 QQQQQ42 QQQQQ94 RRRRR147 RRRRR199 RRRRR251 RRRRR43 RRRRR95 SSSSS148 SSSSS200 SSSSS252 | SSSSS44 SSSSS96 TTTTT149 TTTTT201 TTTTT253 TTTTT45 TTTTT97 | UUUUU150 UUUUU202 UUUUU254 UUUUU46 UUUUU98 VVVVV151 VVVVV203 VVVVV255 VVVVV47 | VVVVV99 WWWWW100 WWWWW152 WWWWW204 WWWWW256 WWWWW48 XXXXX101 XXXXX153 XXXXX205 XXXXX257 | XXXXX49 YYYYY102 YYYYY154 YYYYY206 YYYYY258 YYYYY50 ZZZZZ103 ZZZZZ155 ZZZZZ207 ZZZZZ259 ZZZZZ51 | aaaaa0 aaaaa104 aaaaa156 aaaaa208 aaaaa260 aaaaa52 bbbbb1 bbbbb105 bbbbb157 bbbbb209 bbbbb261]
Level: 0
Keys: [bbbbb53 ddddd55 fffff5 hhhhh7 kkkkk10 lllll63 ooooo14 qqqqq120 sssss18 ttttt71 vvvvv73 xxxxx23]
Vals: [bbbbb53 ccccc106 ccccc158 ccccc2 ccccc210 ccccc262 ccccc54 ddddd107 ddddd159 ddddd211 ddddd263 ddddd3 | ddddd55 eeeee108 eeeee160 eeeee212 eeeee264 eeeee4 eeeee56 fffff109 fffff161 fffff213 fffff265 | fffff5 fffff57 ggggg110 ggggg162 ggggg214 ggggg266 ggggg58 ggggg6 hhhhh111 hhhhh163 hhhhh215 hhhhh267 hhhhh59 | hhhhh7 iiiii112 iiiii164 iiiii216 iiiii268 iiiii60 iiiii8 jjjjj113 jjjjj165 jjjjj217 jjjjj269 jjjjj61 jjjjj9 | kkkkk10 kkkkk114 kkkkk166 kkkkk218 kkkkk270 kkkkk62 lllll11 lllll115 lllll167 lllll219 lllll271 | lllll63 mmmmm116 mmmmm12 mmmmm168 mmmmm220 mmmmm272 mmmmm64 nnnnn117 nnnnn13 nnnnn169 nnnnn221 nnnnn273 nnnnn65 ooooo118 | ooooo14 ooooo170 ooooo222 ooooo274 ooooo66 ppppp119 ppppp15 ppppp171 ppppp223 ppppp275 ppppp67 | qqqqq120 qqqqq16 qqqqq172 qqqqq224 qqqqq276 qqqqq68 rrrrr121 rrrrr17 rrrrr173 rrrrr225 rrrrr277 rrrrr69 sssss122 sssss174 | sssss18 sssss226 sssss70 ttttt123 ttttt175 ttttt19 ttttt227 | ttttt71 uuuuu124 uuuuu176 uuuuu20 uuuuu228 uuuuu72 vvvvv125 vvvvv177 vvvvv21 vvvvv229 | vvvvv73 wwwww126 wwwww178 wwwww22 wwwww230 wwwww74 xxxxx127 xxxxx179 | xxxxx23 xxxxx231 xxxxx75 yyyyy128 yyyyy180 yyyyy232 yyyyy24 yyyyy76 zzzzz129 zzzzz181 zzzzz233 zzzzz25 zzzzz77]]ロック制御
ロック制御について、元のコードだとsynchronizedなどJavaの機能を利用したものになってますが、これをGo向けに大きく書き換える必要がありました。
go routineを1つループさせて、channelでロック取得・解除をさせるようにしてみました。
ただ、たまにロック解除にpanic起こす・そこまでテストできていない、など課題あり。どう対応すればよいかもう少し探りたいところ。 ちょうど似た課題のJava→Go移植の記事が出ていたので、さらに理解深めたいと思います。
ちょっとJavaのsynchronizedをGoに移植しようとしたはずが、なぜか1万文字の作文ができた - エムスリーテックブログ
おわりに
昨年末ごろから軽い気持ちで始めた自作RDBMSですが、思ってたよりずっと大変で、半年以上かけてここまでたどりつきました。他のことして逃げながらもなんとか書籍の範囲は完走できて達成感感じてます。
もちろん磨き上げるべき箇所はいくらでもあるので、気が向いたらさらに直していきたいところです。『効率的なGo』のプラクティス使って最適化さらに進めるとかやりたい、が一旦は他の先延ばしにしてる違うことやってくかな。。
当初のモチベーションにあった、内部実装の理解を深めるという点はかなり達成できた気はします。 B-Treeのページングなども考慮しながらの実装、トランザクションでのロック機構の実装など、苦しんで対応したことでよりRDBMSへのリスペクトが強固なものになりました。 一部写経だけ頑張った!みたいなところもあるので書籍読み返して解像度上げたいです。
辛いながらもそこから得られる経験は多くあるので、気になる方はぜひチャレンジしてみてください。 途中でも紹介した『自作RDBMSやろうぜ!』には他の入口も紹介されているので、自分にあったやり方を見つけてみましょう!
